At Aalpha Information Systems, we safeguard every project with strict compliance, strong encryption, and clear governance. Client data, intellectual property, and digital assets stay protected while we maintain reliability and trust in all operations.







18+
years of building bespoke software, transforming businesses across industries.
We offer a wide range of services meeting your specific business needs
AI Development
We build intelligent, data-driven systems that enhance automation, accuracy, and decision-making across business functions.
- Generative AI Solutions
- AI Chatbots & Virtual Assistants
- Predictive Analytics & Machine Learning
Software Development
From custom business tools to large-scale enterprise applications, we develop robust software that scales with your goals.
- Custom Software Solutions
- Enterprise Resource Planning (ERP) Systems
- Business Process Automation
Web Development
We craft secure, scalable, and AI-enhanced web platforms tailored to your operational and customer needs.
- Progressive Web Applications (PWAs)
- Single Page Applications (SPAs)
- Enterprise Web Portals

Web Application Development
We build fast, secure, and scalable web applications tailored to business workflows and user needs.
- Custom Web Applications
- Enterprise Portals
- Frontend & Backend Development
Mobile Development
We build native and cross-platform mobile applications engineered for performance, usability, and scalability.
- Android & iOS App Development
- Cross-Platform Apps
- AI-Integrated Mobile Solutions

SaaS Development
We specialize in cloud-based SaaS product engineering that ensures reliability, seamless scaling, and subscription-based growth.
- Multi-Tenant SaaS Platforms
- API Integrations
- AI-Based Subscription Analytics

eCommerce Development
Our eCommerce solutions combine conversion optimization, automation, and intelligent analytics for growth-driven platforms.
- B2B/B2C Online Stores
- Marketplace Platforms
- AI-Powered Product Recommendation Systems

MVP Development
We help startups and enterprises validate ideas quickly with functional, investor-ready MVPs powered by AI insights.
- Prototype to Launch
- Core Feature Development
- Rapid Testing & Iteration

Cloud Application Development
We build and deploy cloud-native applications with advanced automation, monitoring, and scalability features.
- Cloud-Native Development
- Migration & Modernization
- AI-Based Infrastructure Optimization
GET A FREE ESTIMATE
Want To Grow your Business ?
Accelerate innovation with AI-led software solutions tailored to your specific goals. From product strategy to full-scale deployment, Aalpha provides end-to-end IT expertise to help your business outperform competitors.
By submitting this form, your agree to our Terms of Service and Privacy Policy.
We Create New Solutions With Technology That Beat Industry Best Timelines
AI Agent Development
We develop intelligent AI agents capable of automating decision-making, communication, and
business processes. These systems operate independently, adapt to user behavior, and
continuously learn to improve efficiency and accuracy across operations.
Machine Learning Development
Our machine learning services help organizations turn raw data into strategic insights. We
build and deploy models that enable predictive analytics, process optimization, and
intelligent automation across diverse industry use cases.
Chatbot Development
We design conversational AI chatbots that deliver human-like interactions and instant
support across websites, apps, and messaging channels. Our chatbots enhance customer
engagement, reduce support costs, and ensure round-the-clock availability.
Robotic Process Automation
Aalpha implements RPA solutions that replace repetitive manual workflows with high-speed
automation. Our intelligent bots handle complex operations with precision, helping
enterprises save time, reduce errors, and boost overall productivity.
Data Science Consulting
Our data science consulting practice enables organizations to make smarter, evidence-based
decisions. We leverage advanced analytics, statistical modeling, and AI algorithms to
uncover patterns that directly improve business performance.
Natural Language Processing
We integrate NLP technology to help machines understand, interpret, and respond to human
language. Our NLP models power search engines, chatbots, sentiment analysis systems, and
voice-driven business applications.
Video Analytics
Aalpha builds video analytics platforms that use AI to identify patterns, detect activities,
and deliver actionable insights in real time. From surveillance to retail intelligence, our
systems bring automation to visual data processing.
ChatGPT Application Development
We develop enterprise-grade applications powered by ChatGPT to automate communication,
streamline workflows, and generate content intelligently. Each deployment is fine-tuned for
domain-specific accuracy and real-world usability.
Blockchain Development
Our blockchain expertise enables secure, transparent, and tamper-proof digital ecosystems.
We build decentralized platforms and smart contract systems that improve trust, compliance,
and traceability across business networks.
Web3 Development
We help businesses transition to the decentralized web with custom Web3 solutions. From NFT
platforms to DAO applications, our Web3 products empower organizations to innovate in
blockchain-driven digital economies.
Microservices Development
Aalpha engineers microservices architectures that enhance scalability, maintainability, and
deployment speed. Our modular approach allows businesses to evolve their software systems
efficiently without downtime or performance loss.
FOR MORE INFORMATION
Ask From
Our Expert
7,000+ Completed Projects in
45+ Countries
Aalpha has successfully delivered AI-powered IT solutions across diverse industries, from healthcare and logistics to fintech and manufacturing. Our proven delivery model ensures on-time execution and measurable success.
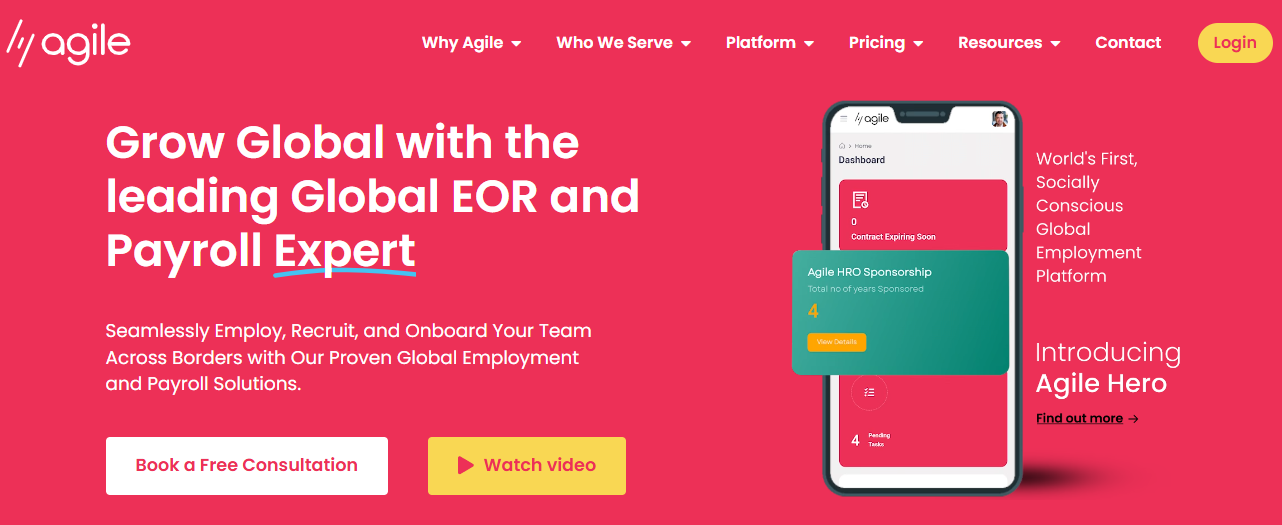
AgileHRO – Global HR Tech Platform Built for Seamless International Expansion
Aalpha developed a comprehensive SaaS HR tech platform for AgileHRO using a Microservices architecture with Laravel and Angular. The platform supports global hiring, legal employment of local staff, payroll management, international relocation needs, and access to worldwide talent pools. Designed for flexibility and scale, it helps businesses overcome common expansion barriers and manage remote teams with confidence. This project showcases Aalpha’s ability to build robust, scalable digital solutions tailored for complex global operations.
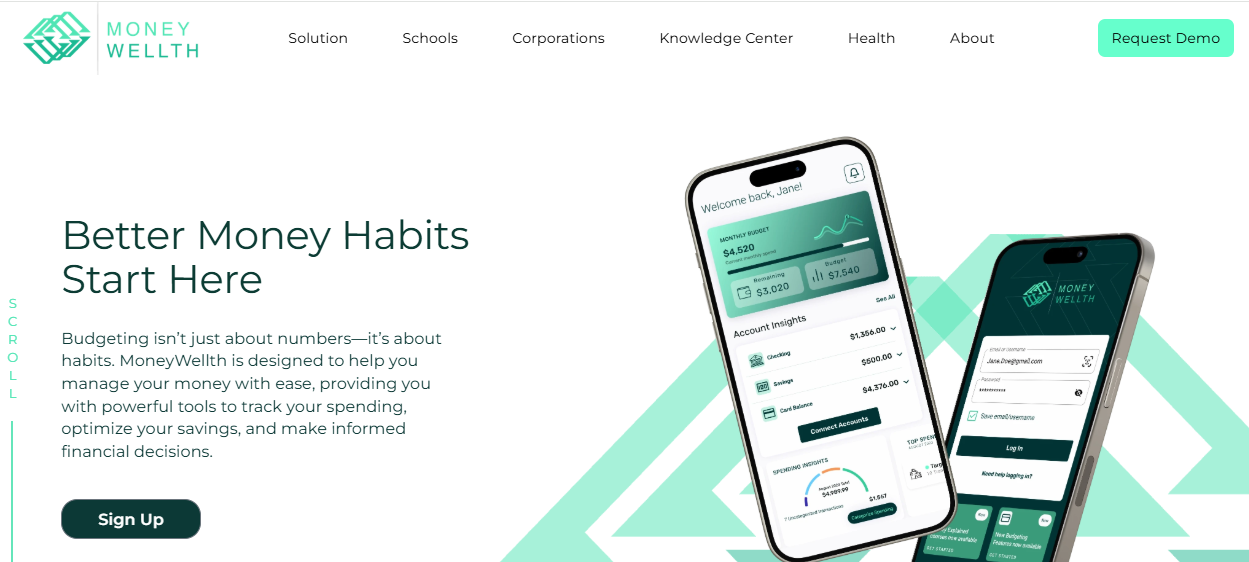
MoneyWellth – Multi-Platform Fintech Solution for Smarter Financial Decisions
Aalpha developed MoneyWellth as a SaaS financial management platform for iOS, Android, and the web. It supports key life events-such as home buying and family planning-while offering tools for spending analysis, automated savings, debt management, and credit improvement. The platform also guides users in investing, retirement planning, insurance, and wealth building, helping them make informed financial choices across devices.
VisaBud – Digital Visa Application Marketplace Built for Simplicity and Speed
Aalpha developed VisaBud as a marketplace-style platform that removes the complexity from the visa application process. Accessible on mobile and desktop, the platform allows users to view visa requirements based on their citizenship and destination. Known for its ease of use and efficient workflows, VisaBud showcases Aalpha’s ability to deliver fast, reliable, and user-centric digital solutions for complex processes.
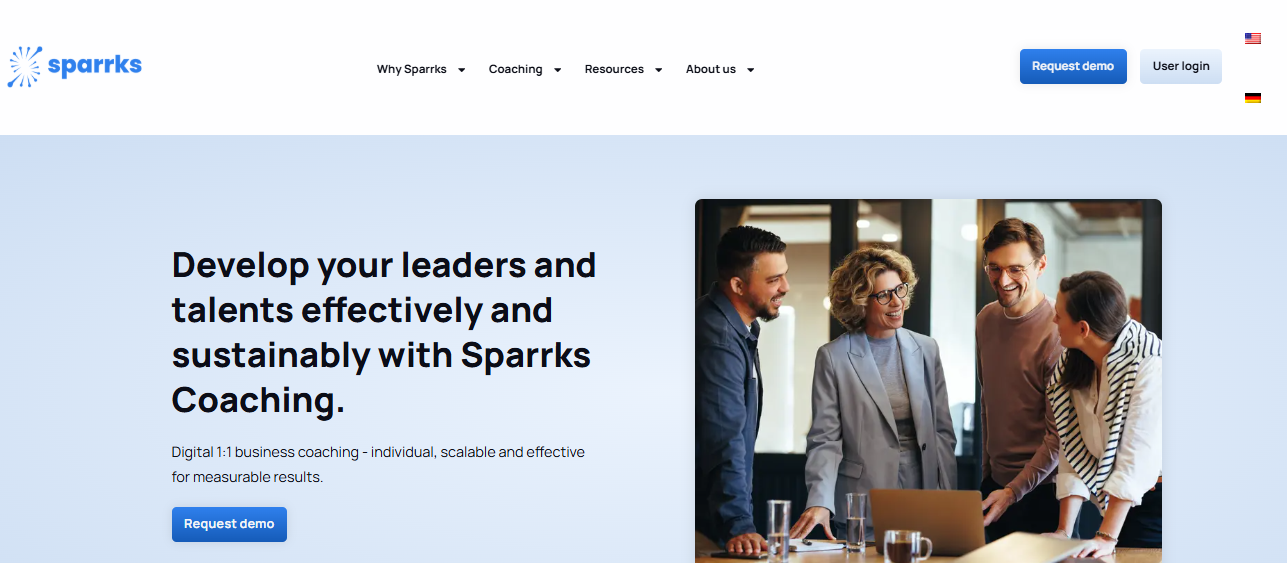
Sparrks – High-Impact Coaching SaaS Platform for Leadership and Talent Growth
Aalpha built the SaaS platform that powers Sparrks’ premium 1:1 business coaching experience. Developed with a microservices architecture and real-time video capabilities, the system supports focused coaching journeys delivered by top-tier executive coaches. Sparrks is recognized for driving measurable outcomes, including a 76% rise in individual performance, 7x ROI, and stronger talent retention. The platform enhances leadership development programs, supports change initiatives, and enables scalable digital coaching across organizations.
Domain Expertise
Agritech
Finance & Insurance
Food & Beverage
Manufacturing
Education
Media & Publishing
Engineering
Hospitality & Travel
Food & Beverage
Manufacturing
Education
Media & Publishing
Agritech
Finance & Insurance
Engineering
Hospitality & Travel
Technologies and Platforms We Work With
HTML
CSS
JavaScript
React
Angular
Vue.js
Node.js
Python
Laravel
PHP
Java
WordPress
Android
Flutter
React Native
MySQL
MongoDB
Adobe XD
Figma
Our Clients Have Some Great Words For Us
Our Work Process
We follow a transparent and agile development process that ensures efficiency, quality, and measurable results. Every project is guided by collaboration, continuous feedback, and data-driven decision-making, helping clients achieve faster delivery without compromising on performance or reliability.
STEP 1
Discovery & Strategy
Understanding business goals, defining scope, and identifying the right technology approach.
STEP 2
Design & Architecture
Creating scalable system blueprints and intuitive user experiences.
STEP 3
Development & Integration
Building high-quality, secure software with modern frameworks and proven methodologies.
STEP 4
Testing & Quality Assurance
Ensuring stability, performance, and seamless user experience through rigorous validation.
STEP 5
Launch & Continuous Optimization
Deploying efficiently, monitoring results, and refining for long-term success.
Our Achievements
Aalpha has delivered thousands of technology projects worldwide, combining innovation, reliability, and on-time delivery. Each milestone reflects our commitment to quality engineering and lasting client success.
1500+
Clients
7,000+
Projects Completed
45+
Countries
250+
Skilled Staff
Testimonials

Jeff Schreibman
CEO of Merch Free Poker

Jasper Robles
CEO (Confidential Company)

Patrick Manifold
CEO (Confidential Company)
Our clients trust us because we consistently deliver — on time, on budget, and with uncompromising quality.
Meet Our Experts
Our team brings deep technical expertise and hands-on industry experience to every project. They combine strategic thinking with precise execution to deliver solutions that move your business forward.

Security, Compliance & Trust
Data Protection and Privacy
We ensure complete data security across every stage of development, safeguarding client
information with advanced encryption and strict access controls.
- End-to-end Encryption
- Secure Authentication
- Regular Security Audits
Compliance Framework
Aalpha adheres to globally recognized compliance standards to maintain trust, transparency, and
legal integrity in all projects.
- GDPR and HIPAA Compliance
- ISO 27001 Certified Practices
- Continuous Policy Reviews
Intellectual Property Protection
We protect your proprietary assets and confidential information with robust legal and technical
safeguards.
- Non-Disclosure Agreements (NDAs)
- Source Code Ownership Transfer
- Secure Repository Management
Quality Assurance
Our QA teams follow structured testing processes to ensure reliability, usability, and flawless
performance before deployment.
- Automated and Manual Testing
- Continuous Integration & Monitoring
- Bug Tracking and Regression Validation
Frequently Asked Questions
Aalpha offers end-to-end IT solutions including web and mobile app development, enterprise software, SaaS platforms, AI-powered systems, and cloud application development. We serve businesses of all sizes across multiple industries worldwide.
We follow strict security protocols with end-to-end encryption, secure authentication, and regular audits. Our team adheres to global compliance standards such as GDPR, HIPAA, and ISO 27001 to protect sensitive information at every stage.
Yes. We specialize in designing and developing scalable, enterprise-grade software tailored to specific business requirements, ensuring seamless integration, security, and long-term performance.
We use artificial intelligence to automate workflows, enhance data analytics, improve decision-making, and optimize user experiences. Our expertise includes AI agents, machine learning, and ChatGPT-based applications.
Aalpha has extensive experience across healthcare, logistics, fintech, retail, manufacturing, education, travel, and media. Each project is customized to the compliance and operational needs of the respective industry.
We use an agile development methodology focused on collaboration, transparency, and timely delivery. Every project includes clear milestones, continuous testing, and regular client feedback loops to ensure predictable outcomes.
Global clients choose Aalpha for our proven track record, transparent communication, and ability to deliver complex IT solutions on time and within budget. Our combination of technical excellence, strategic insight, and long-term support makes us a trusted partner for digital transformation.
You can request a free consultation or project proposal directly through our website. Our team will analyze your requirements, provide cost estimates, and create a tailored development plan aligned with your business goals.